Interview
Lynn Kaack:
An der Schnittstelle
von Klimaschutz und
Künstlicher Intelligenz

Zur Person
Lynn Kaack ist seit 2021 Professorin für Computer Science und Public Policy an der Hertie School in Berlin. Zuvor befasste sie sich in der Forschungsgruppe „Energy Politics Group“ an der Eidgenössischen Technischen Hochschule (ETH) Zürich damit, wie maschinelles Lernen in verschiedenen Bereichen für Klimaschutz eingesetzt werden kann. Sie forscht an wissenschaftlichen und methodischen Grundlagen der Energiepolitik. An der Carnegie Mellon University promovierte sie am Fachbereich „Engineering and Public Policy“. Kaack ist außerdem Co-Leiterin der internationalen Expertinnen- und Experten-Gruppe „Climate Change AI“, die 2019 und 2020 insgesamt fünf Konferenz-Tracks zum Thema organisierte und ein Online-Netzwerk betreibt. Sie ist Mitglied im Österreichischen Rat für Robotik und Künstliche Intelligenz, ein Beratungsorgan des Bundesministeriums für Klimaschutz, Umwelt, Energie, Mobilität, Innovation und Technologie.
- Climate Change AI, https://www.climatechange.ai Energy Politics Group (Prof. Dr. Tobias Schmidt),
- ETH Zürich, https://epg.ethz.ch/people/alumni/dr--lynn-kaack.html
Essential
Lynn Kaack erforscht, wie Methoden des maschinellen Lernens für Policy-Analysis eingesetzt werden können. Dabei arbeitet sie an Projekten im Energie-, Verkehrs-, Finanz- und Gebäudesektor. Sie hält interdisziplinäres Arbeiten in Forschung, Unternehmen und Politik für wichtig, weshalb sie sich seit 2019 für die Vernetzung der Akteure im Rahmen der internationalen Experteninnen- und Experten-Gruppe namens „Climate Change AI“ als Mitgründerin und -leiterin einsetzt. Die Gruppe stellt mit Veröffentlichungen, Workshops und Aktivitäten auf internationalen Konferenzen eine Plattform für die Schnittstelle von Klima und KI.
Maschinelles Lernen kann für zahlreiche Anwendungen im Bereich Klimaschutz und -adaption eingesetzt werden, doch in der Praxis steht man nach Beobachtung von Kaack oftmals noch ganz am Anfang. Sie erläutert, dass hierfür mehr interdisziplinäre Zusammenarbeit nötig ist, die bisher in vielen Forschungseinrichtungen so noch nicht gegeben ist. Auch der Privatsektor und öffentliche Einrichtungen müssten stärker involviert werden. Dies könne daran liegen, dass sich der KI-Bereich rasant entwickelt hat und viele dieser Anwendungsbereiche noch Neuland für die Disziplinen sind. An Beispielen aus dem Verkehrs- und Finanzsektor schildert Kaack den hohen Aufwand für originäre Datengenerierung und -aufarbeitung, der für eine gute Modellbildung unerlässlich ist. Dabei sieht sie die Chance für die Wissenschaft, sozialverträgliche Datensätze zu kreieren.

Empfohlener redaktioneller Inhalt
An dieser Stelle finden Sie einen externen Inhalt von YouTube, der den Artikel ergänzt. Sie können ihn sich mit einem Klick anzeigen lassen und wieder ausblenden.
Interview
An der Schnittstelle von Klima und Künstlicher Intelligenz
- Was kann maschinelles Lernen für den Klimaschutz beitragen?
- Lynn Kaack: Maschinelles Lernen als Methode kann sehr breit für klimaschutzrelevante Themen angewandt werden. Es kann sehr gut mit ungeordneten Daten umgehen, um aus ihnen nichtlineare Funktionen herauszulesen. Das kann für kurz- und mittelfristige Vorhersagen hilfreich sein, wie sie beispielsweise im Energiesektor bereits angewandt werden. Es kann auch für Bilderkennung in der Fernerkundung angewandt werden, wie etwa der Beobachtung von Vegetation oder der Erfassung von Infrastrukturdaten wie Gebäudebeständen. Vorausschauende Instandhaltung kann damit verbessert werden, etwa durch eine vereinfachte automatisierte Fehlererkennung. Das ist für die gesamte Industrie wichtig, kann aber auch für erneuerbare Energien angewendet werden oder für Infrastrukturen wie Bahn und Bus. Mithilfe von Machine Learning können auch Rechenprozesse für komplexe Simulationen beschleunigt werden. Solche Simulationsmodelle ziehen sich durch den ganzen Bereich klimarelevanter Themen, von Klimawissenschaften bis hin zur Modellierung einzelner Gebäude. Wichtig für Entscheidungsträger ist es, aus solchen Modellen schnell Schlüsse ziehen zu können, wobei mit maschinellem Lernen die Laufzeit der Simulationen deutlich verringert werden kann.
- Sie haben zusammen mit anderen Forschern 2019 das Paper „Tackling Climate Change with Machine Learning“ veröffentlicht, das sich mit der Frage befasst, wie man mit KI-Techniken Klimaschutz und Klimaadaption befördern kann.1 Was hat Sie zu diesem Schritt motiviert?
- Lynn Kaack: Mein Interesse ist über die Zeit gewachsen. Ich hatte für meine Dissertation im Fachbereich Engineering and Public Policy an der Carnegie Mellon University an Klimathemen im Policy-Bereich geforscht, aber nebenher aus Interesse auch einen Master für maschinelles Lernen absolviert. Mit einem Projekt zur Fernerkundung des weltweiten LKW-Verkehrs habe ich versucht, beide Themen zu verbinden.2
So ein Ansatz war damals für die Energie-Forschungscommunity relativ neu, ich fühlte mich gleichzeitig aber auch nicht in der Machine-Learning-Gemeinschaft zu Hause, da mein Projekt für diese Forschung zu angewandt war. Im letzten Kapitel meiner Dissertation schrieb ich dann einen kleinen Überblick darüber, wie Machine Learning für Klimaschutz verwendet werden kann. Das war einer der Vorläufer für das Paper „Tackling Climate Change with Machine Learning“.
- Ohne einen interdisziplinären Ansatz geht es also nicht?
- Lynn Kaack: An der Carnegie Mellon University gibt es einen guten interdisziplinären Austausch und das maschinelle Lernen reicht in viele Fachbereiche hinein. Eine Kommilitonin von mir, die einen Joint PhD in Computer Science und Energiepolitik macht, hatte auf der internationalen KI-Konferenz NeurIPS 2018 viele andere KI-Forscher kennengelernt, die Interesse hatten, im Bereich Klimaschutz zu arbeiten. Wir haben dann das Paper „Tackling Climate Change with Machine Learning“ in den folgenden Monaten geschrieben und einen Workshop zum Thema organisiert. Daraus ist die Gruppe „Climate Change AI“ entstanden. Wir haben viel Anklang bei anderen Forschern gefunden, die ebenfalls an der Schnittstelle von Klima und Künstlicher Intelligenz arbeiten.
- Wie hat sich „Climate Change AI“ weiterentwickelt?
- Lynn Kaack: Uns wurde bewusst, dass es wirklich einen Bedarf für eine Austauschplattform beziehungsweise ein akademisches Zuhause für diesen Bereich gibt. Wir sind aber rasch über den akademischen Bereich hinausgegangen und binden inzwischen Unternehmen, Start-ups und Politikinteressierte ein. Denn für den Klimaschutz ist es wichtig, dass in der wirklichen Welt etwas passiert, und nicht nur, dass etwas veröffentlicht wird. Inzwischen organisieren wir regelmäßig ganztägige Workshops auf Konferenzen und momentan viele virtuelle Events. Das Interesse am Thema ist groß: Unser Newsletter hat zum Beispiel über 4.000 Abonnenten und wir wurden vor einem Jahr auch auf die Klimakonferenz COP25 eingeladen.
- Die Forschungsgruppe „Energy Politics Group“ an der Eidgenössischen Technischen Hochschule (ETH) Zürich forscht auf Gebieten, die relevant für Politikberatung sind. Welche praktischen Erfahrungen konnten Sie hier bereits machen?
- Lynn Kaack: In der Energy Politics Group beschäftigen wir uns mit Fragestellungen zum Thema Klimaschutz im Energiebereich und sind mit Ingenieuren, Politikwissenschaftlern und Wirtschaftswissenschaftlern interdisziplinär aufgestellt. Es gibt Arbeiten zu den unterschiedlichsten Themen an der Schnittstelle von Politik und Technik. Wir schauen uns beispielsweise an, wie Kosten von Batteriesystemen reduziert wurden und werden. Viele von uns geben Denkanstöße an die Politik weiter, zum Beispiel in Hearings, Workshops oder über Policy Briefs. Ich selbst gebe relativ oft Inputs, ganz besonders zum Thema KI und Klima.
- 1) Rolnick, D. et al. (2019): Tackling Climate Change with Machine Learning. ArXiv, https://arxiv.org/abs/1906.05433
- 2) Kaack, L. H., Chen, G. H. & Granger Morgan, G. (2019): Truck traffic monitoring with satellite images. Proceedings of the Conference on Computing & Sustainable Societies (COMPASS '19). ACM, New York, NY, USA, S. 155 – 164.
- 1
- vorwärts
Orientierungswissen für Klimapolitik generieren
- Welche Arbeitsziele verfolgt die Gruppe?
- Lynn Kaack: Wir definieren die Ziele weniger normativ, sondern arbeiten eher an Bestandsaufnahmen, die als Entscheidungshilfen dienen können. Beispielsweise sehe ich mir mit meinen Kollegen an, wie Fortschritte im Bereich erneuerbarer Energien in Patenten beschrieben werden. Daraus können wir ableiten, ob es für eine bestimmte Technologie ausschlaggebender ist, dass Produktionsprozesse verbessert werden oder dass sich das Design des Produkts weiterentwickelt. Der erste Fall ist bei Solarzellen wichtiger und der zweite zum Beispiel bei der Windenergie. Diese Unterscheidung hat Einfluss darauf, wie man politische Instrumente gestaltet. Auf diese Weise können wir also ex ante zu einer bevorstehenden Entscheidung Hilfe leisten. Manchmal sind wir aber auch daran interessiert, ex post festzustellen, wie sich eine bestimmte Politik ausgewirkt hat.
- Welche Rolle spielt hier maschinelles Lernen?
- Lynn Kaack: Mir geht es darum, mit maschinellem Lernen Daten zu generieren, die wir vorher nicht hatten. Zum Beispiel werden für solche Untersuchungen große Text-Datenbanken manuell durchgelesen. In unserem Patent-Projekt übernahmen das Studierende. Ein solcher Prozess dauert allerdings lange und lässt sich damit nur auf eine kleine Auswahl der Texte anwenden. Maschinelles Lernen kann hier zu einem gewissen Grad helfen, Texte automatisch auszulesen. Wir haben die kleine Auswahl der Patente dann dazu benutzt, einen Algorithmus zu trainieren, und können so die Erkenntnisse anhand des gesamten Datensatzes gewinnen, der aus Tausenden Patenten besteht. Das hat hier gut funktioniert. Solche Analysen stecken insgesamt aber noch in den Kinderschuhen: Die Spracherkennung generell macht gerade große Sprünge, aber es ist noch nicht so, dass man sie darauf trainieren kann, Texte durchzulesen und dann den Inhalt wiederzugeben. Wie gut das klappt, hängt von der Fragestellung ab.
- Was wäre ein Beispiel dafür, massenhaft Daten auf bestimmte Werte hin zu untersuchen?
- Lynn Kaack: Wir interessieren uns in einem anderen Projekt zu erneuerbaren Energien für das Design von Gesetzgebung. Dabei geht es uns um spezifische Fragen wie: Geht das Gesetz auf bestimmte Technologien ein, erhalten bestimmte Institutionen Geld und welche Institutionen sind für die Einhaltung des Gesetzes zuständig? Dafür bauen wir mit Studierenden einen Datensatz auf, mit dem verschiedene Modelle für maschinelles Lernen trainiert werden sollen. Für diesen Datensatz codieren wir eine Auswahl von Gesetzen der Europäischen Union und aus den USA und schauen, ob sich Modelle entwickeln lassen, die die Analyse dann auf die vielen Hunderte oder Tausende Gesetzestexte ausweiten können, die man sich eigentlich gerne anschauen möchte.

- Wo erhoffen Sie sich dank automatisierter Analyse einen höheren Erkenntniswert?
- Lynn Kaack: Werden Datenbanken für Fragestellungen in der Policy-Analyse manuell ausgewertet, wird eher allgemein gefragt: Hat dieses Land Gesetzgebung, die den Ausbau Erneuerbarer fördert? Dann wird meistens nur ein Datenpunkt genommen, nämlich: „Es gibt ein Gesetz.“ Aber man möchte schon wissen, wie so ein Gesetz aufgebaut ist, und uns fehlen da systematische Daten. Wenn man detailliertere Datensätze hat, hilft es also, die Policy-Landschaft besser zu verstehen.
- Welche Fragen könnte man aus dem Gesetzesdesign ableiten?
- Lynn Kaack: Zum Beispiel: Wer genau sind die Adressaten und was müssen sie tun? Ist die Regulierung detaillierter, wenn es um erneuerbare Energien geht und nicht um herkömmliche Energieträger? Wie komplex ist es für Anwender in der Praxis, ein Gesetz zu verstehen? Stellt die Komplexität des Gesetzes eine Barriere dar? Wir codieren im Moment noch die Texte und werden dann sehen, welche Modelle wir benutzen oder erstellen können, um verschiedene Parameter auszulesen. Dazu gehören beispielsweise Deadlines für die Implementierung oder monetäre Beträge für bestimmte Aktionen.
- zurück
- 2
- vorwärts
Arbeiten an der Schnittstelle von KI und Nachhaltigkeit
- Worin besteht die fachliche Herausforderung?
- Lynn Kaack: Wir erleben hier ein generelles Problem im Bereich von maschinellem Lernen: Es gibt viele Fortschritte in der Grundlagenforschung, doch in der Anwendung hapert es an vielen Seiten, vor allem aber an Kapazitäten und Erfahrung. Maschinelles Lernen ist momentan noch sehr neu in vielen Bereichen. Das heißt, dass es einen Mangel an Fachkräften geben kann, dass bestehende Abläufe nicht darauf ausgerichtet sind, solche Analysen mit einzubeziehen, und dass es einen Mangel an Vertrauen in diese neuen Modelle geben kann. Oft kommt es nicht einmal zur Entwicklung solcher Ansätze, weil diejenigen, die sich mit den spezifischen Fragestellungen auskennen, nicht über das nötige Wissen im KI-Bereich verfügen, oder andersherum. Das ändert sich nur, wenn mehr Menschen interdisziplinär zu verschiedenen Fragestellungen arbeiten.
- Wo sehen Sie die relevantesten Entwicklungspfade für maschinelles Lernen im Bereich des Klimaschutzes?
- Lynn Kaack: Das ist schwierig zu sagen, da es dazu keine Zahlen gibt. Dafür muss man nicht nur zukünftige Entwicklungen in klimarelevanten Sektoren abschätzen, was mit vielen Unsicherheiten verbunden ist, sondern gleichzeitig genau verstehen, wie sich der Mehrwert des maschinellen Lernens beziffern lässt. Es geht hier auch oft nicht um ein Entweder-oder, denn der Klimawandel muss auf vielen Ebenen gleichzeitig angegangen werden. Ich persönlich bin sehr daran interessiert, wie wir maschinelles Lernen dazu benutzen können, Entscheidungsträgern im öffentlichen Bereich bessere Informationen bereitzustellen.
- Welches Potenzial hat denn maschinelles Lernen in der Politikanalyse?
- Lynn Kaack: Es gibt heutzutage unglaublich viele neue Datensätze und Analysemöglichkeiten, die man meiner Meinung nach nutzen sollte. Informationen im Bereich Politikberatung sind bislang oft minimiert, und viele Analysen beruhen zum Beispiel auf Expertenwissen, das man über Befragungen erhebt. Maschinelles Lernen kann hier unter Umständen eine Rolle spielen, ich selbst sehe es aber definitiv nicht als Allheilmittel. Die Policy-Analyse steht in diesem Bereich auch eher am Anfang.
- Was konnte denn Ihre LKW-Analyse an neuen Erkenntnissen im Policy-Bereich beisteuern?
- Lynn Kaack: In einer Studie hatte ich mir die Dekarbonisierung des Landverkehrs angeschaut.3 Dabei habe ich festgestellt, dass viele Länder gar keine Daten über den Frachtverkehr auf der Straße erheben oder veröffentlichen. Für einige Länder sind vorhandene Daten dann auch veraltet oder werden nur unregelmäßig erhoben. In vielen Ländern werden nicht einmal Verkehrszählungen gemacht oder nur sehr kurzzeitige. In den meisten Industrieländern gibt es automatisierte Verkehrszählungen zwar an großen Straßen, aber nicht flächendeckend.
„Was die Daten lehren können, lernt das System“
Während meiner Promotion hatte ich die Idee, dass man den LKW-Verkehr mithilfe von Satellitenbildern überprüfen könnte, und hatte mir Folgendes überlegt: Aus automatisiert ausgezählten LKWs wollte ich berechnen, wie hoch der Verkehrsfluss auf der Straße ist. Das Problem war, dass oft nur ein Bild pro Straße zur Verfügung stand, wir interessierten uns aber für einen jährlichen Mittelwert. Mit Blick darauf, dass ein sehr unsicherer Datenpunkt zu erhalten ist, musste auch die Unsicherheit bemessen werden. Das habe ich dann gemacht. Die Hauptarbeit bestand darin, den Objekterkennungsalgorithmus auf die LKWs zu trainieren. Ich hatte Glück, dass mir Satellitenbilder mit einer Auflösung von 31 Zentimetern zur Verfügung gestellt wurden. Ich habe mich abends hingesetzt und insgesamt über 5.000 LKWs gelabelt, also in den Bildern um einen LKW ein Kästchen gezogen. Zum Glück muss man nicht mehr so wach sein, um das zu tun.
- 3) Kaack, L. H. et al. (2018): Decarbonizing intraregional freight systems with a focus on modal shift. Environmental Research Letters, 13; Online unter: https://iopscience.iop.org/article/10.1088/1748-9326/aad56c/pdf
- zurück
- 3
- vorwärts
- Gab es keine Möglichkeit, das Labeln über eine Captcha- Anwendung machen zu lassen?
- Lynn Kaack: Ich durfte diese Bilder nicht mit anderen teilen, weshalb Captcha-Dienste dafür nicht geeignet waren. Man möchte auch gute Daten haben. Was gerne in der Diskussion um maschinelles Lernen übersehen wird, ist, dass es unglaublich viel Arbeit auf der Datenseite gibt. Für das Aufsetzen der Infrastruktur – also sowohl das Annotieren, aber noch viel grundlegender das Säubern und Zusammenführen der Datensätze – müssen ungefähr 80 Prozent der Projektzeit eingerechnet werden. Aber im Paper macht das dann einen Absatz im Anhang aus. Diese Datenaufarbeitung ist unglaublich wichtig und müsste mehr geschätzt werden – entsprechend müsste dafür auch Geld zur Verfügung stehen. Auch für Studierende ist das im Moment relativ unattraktiv. Machine- Learning-Studierende erhalten meistens Datensätze, die fertig sind, und können direkt an den Modellen arbeiten. Im Anwendungsbereich arbeitet man aber mit echten Daten, die sehr viel mehr Arbeit machen.
- Ist die Datengenerierung und -aufarbeitung ein Flaschenhals für die Erforschung von Nachhaltigkeitsfragen?
- Lynn Kaack: Das ist einer von vielen Flaschenhälsen, doch diese Vorgänge lassen sich nur bedingt vereinfachen und sind oft ein wertvoller Teil der Arbeit. Man könnte die Möglichkeiten der Forschungsgruppen erweitern, indem man beispielsweise Gelder für solche Tätigkeiten zur Verfügung stellt – das könnte ein guter Hiwi-Job sein. Andererseits muss es auch mehr wertgeschätzt werden. Eine Modelliererin, ein Modellierer, eine Analystin, ein Analyst, die bzw. der sich mit solchen Modellen beschäftigt, muss besser verstehen, was die Daten überhaupt aussagen. Darin besteht ja die Kernfrage von Künstlicher Intelligenz. Man stellt sich gerne vor, dass man einen Algorithmus auf ein Problem jagt, der dann mysteriöse Antworten gibt, die viel klüger sind als erwartet. In Wahrheit ist es ein statistisches Datenmodell. Was die Daten lehren können, lernt das System.
- Ist das repräsentativ für die Anwendung von KI auf Klimafragen?
- Lynn Kaack: Die Kernleistung bei angewandtem maschinellem Lernen im Nachhaltigkeitsbereich ist die Aufstellung des Problems: Was möchte ich eigentlich lernen? Warum und wie kodifiziere ich etwas in einer maschinenlesbaren Weise? In einem Projekt zur finanziellen Offenlegung beispielsweise interessiert uns, ob in Unternehmensberichten das Thema der Klimarisiken angesprochen wird. Hierfür haben wir als Trainingsdatensatz die Unternehmensberichte von 50 Firmen ausgewählt und erst mal Zeit damit verbracht, die aus PDF-Dateien ausgelesenen Texte in eine Form zu bringen, um sie in Absätze einteilen zu können. Dann haben wir geprüft, welche Kriterien umsetzbar sind und was wir gerne annotieren würden. Das Labeln wird dann wieder viel Zeit kosten. Erst danach können wir damit anfangen, Algorithmen auszuprobieren und Experimente zu fahren.
- Was möchten Sie damit erreichen?
- Lynn Kaack: Man möchte mit maschinellem Lernen möglichst etwas Generalisierbares herstellen. Man muss also das Experiment so gestalten, dass die Resultate aus dem kleinen Rahmen, in dem man es ausprobiert hat, in einem größeren Anwendungsbereich möglichst aussagekräftig sind. Wir möchten auf Basis der automatisierten Analyse der Unternehmensberichte von 50 Firmen etwas generieren, womit man die Berichte mehrerer Hundert oder Tausend Firmen durchgehen kann. Wir halten deshalb bestimmte Firmen aus Testdaten heraus, um später feststellen zu können, wie weit man das Modell auf andere Firmenberichte anwenden kann, die es nie gesehen hat.
Die Qualität der Modelle verändert sich mit den Daten
KI-Anwendungen können auch neue Abhängigkeiten generieren. Ich glaube, viele verstehen nicht, dass solche Modelle über die Zeit immer wieder angeschaut werden müssen. Daten verändern sich, zum Beispiel weil sie anders erhoben werden. Deshalb wird derjenige, der das Experiment erstellt hat, irgendwie involviert bleiben müssen, um sichergehen zu können, dass das Modell macht, was es soll. Aber es ist eher eine Seltenheit im Wissenschaftsbereich, wenn man ein Modell über Jahre oder Jahrzehnte hinweg in der Anwendung betreuen kann.
Die Privatwirtschaft hat da oft einen Vorsprung und mehr Möglichkeiten. Einige Unternehmen haben auch sehr gute selbstgenerierte Daten, die sie für KI-Anwendungen nutzen, und verfügen damit oft über viel bessere Datensätze als die Universitäten. Google zum Beispiel besitzt unglaublich viele Daten über unsere Erde, wie hochauflösende Satellitenbilder oder Straßenkarten. Damit gibt es zum Teil ganz andere Möglichkeiten im privaten Sektor, die öffentlichen Forschungseinrichtungen oft verwehrt bleiben. Zum Glück gibt es auch viele Open-Data-Initiativen und im Klimaschutz arbeiten wir viel mit dem öffentlichen Bereich, wo sich in letzter Zeit ziemlich viel in Sachen Datenmanagement bewegt hat.
- zurück
- 4
- vorwärts
- Heißt das, die veröffentlichten Daten eignen sich inzwischen besser für maschinelles Auslesen?
- Lynn Kaack: Ja, die Datensätze sind vermehrt standardisiert, maschinenlesbar und öffentlich zugänglich. Es gibt inzwischen Standards für Open Government Data, die den behördlichen Datenaustausch und deren Veröffentlichung unterstützen. Hier hat sich viel bewegt. Die Herausforderung besteht darin zu zeigen, was man mit diesen Daten mit maschinellem Lernen machen kann.
Sozialverträgliche Datensätze kreieren
Mit ihrem anderen Blickwinkel kann die Wissenschaft auch dabei helfen, sozialverträgliche Datensätze zu kreieren. Ein Beispiel sind Bewegungsdaten, mit denen man die Planung von Fahrradwegen verbessern könnte. Bewegungsdaten werden zum Beispiel ständig durch Apps auf dem Smartphone gesammelt, jedoch sind das Datensätze, die relativ weit in die Privatsphäre eindringen. Im Idealfall würde man dafür also freiwillig gespendete Daten verwenden. In der Schweiz gibt es genossenschaftliche Modelle, wie etwa die Datengenossenschaft POSMO, die auf diese Weise eine Mobilitätsdatenplattform aufbauen möchte. Diejenigen, die Daten für die Auswertung durch maschinelles Lernen spenden, werden auch an der Datenverwertung beteiligt. An der TU Dresden gibt es Forscher, die im Rahmen des Projekts Movebis ein freiwilliges Datensammlungs-Event zur Erstellung einer Radverkehrsmengenkarte organisieren. Fahrradfahrer zeichnen während der Aktion „Stadtradeln“ drei Wochen lang Daten auf und stellen sie den Forschern zur Auswertung zur Verfügung. Die Motivation dabei ist klar: Fahrradfahrer sind Leute, die ja gerne bessere Fahrradwege hätten und gerne zeigen, wo sie langfahren.
- Wie ließe sich hier Partizipation organisieren?
- Lynn Kaack: Es gibt oft das Problem, dass es einen Selection-Bias gibt, wenn man nur die besonders Engagierten, in diesem Falle die Radfahrer, erfasst. Es besteht immer die Herausforderung, wirklich alle einzubeziehen, um die Ergebnisse repräsentativ zu machen. Hier ist noch viel Raum für Entwicklung.
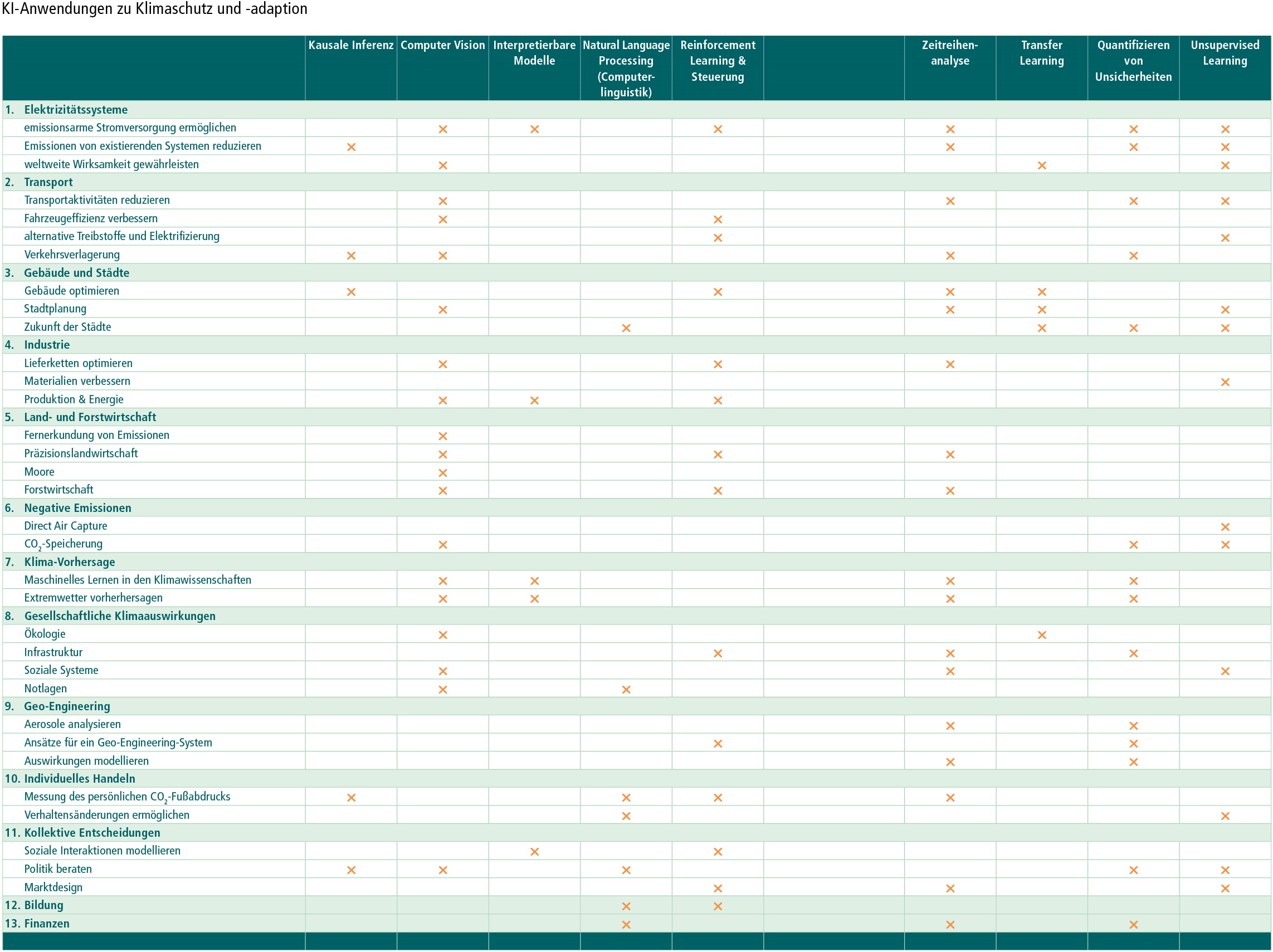
- Quelle: Eigene Darstellung, vgl. Rolnick, D. et al. (2019): Tackling Climate Change with Machine Learning, preprint arXiv:1906.05433, 2019, Online unter: https://arxiv.org/pdf/1906.05433.pdf
- zurück
- 5
Literatur
Rolnick, D. et al. (2019): Tackling Climate Change with Machine Learning. ArXiv, https://arxiv.org/abs/1906.05433
Kaack, L. H., Chen, G. H. & Granger Morgan, M. (2019): Truck traffic monitoring with satellite images. Proceedings of the Conference on Computing & Sustainable Societies (COMPASS '19). ACM, New York, NY, USA, S. 155 – 164.
Das Interview mit Lynn Kaack führte die Journalistin Christiane Schulzki-Haddouti im Rahmen eines vom Bundesministerium für Bildung und Forschung beauftragten Publikationsprojektes zum Thema „KI und Nachhaltigkeit“. Die vollständige Publikation steht als PDF zum Download zur Verfügung.